Trajectories are intriguing
Background
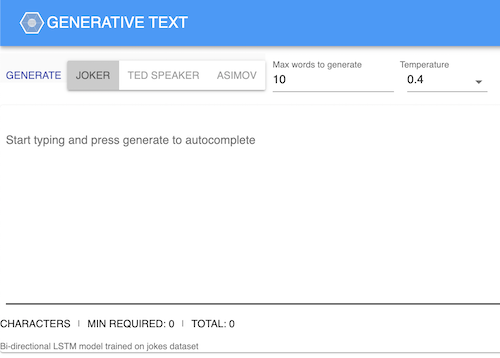
The first version of Word Tree visualized the model trained as part of Neural Text Generation post. It showed the words sampled from a set of small RNN based models trained on various corpora such as Asimov, Jokes, etc. The models were trained along the lines of Karpathy's post on Unreasonable Effectiveness of Recurrent Neural Networks must-read
The demo model used in the neural text generation post was very limiting in terms of their generative capabilities, i.e., consistently producing meaningful suggestions. Nonetheless, it was fascinating to see it uncover the structure of the language. The motivation behind the demo app was to try and create a specialized version of the model that could provide task or domain-specific suggestions. For example, a model to assist in writing jokes or, to auto complete science fiction stories in the style of great Isaac Asimov.
The model architecture will be considered infant compared to the transformers era in terms of the number of parameters, model capacity, and training costs 😉.
I am somewhat surprised to see the demo still working well. I don’t remember touching it at all in the last three years or so.2017: Neural Text Generation Demo Web App (Click Here)
About The Video
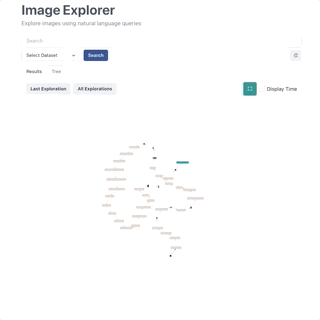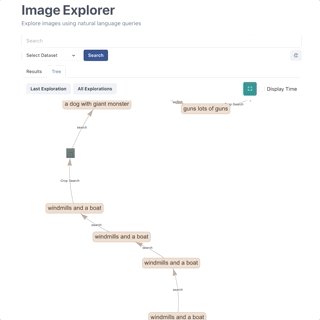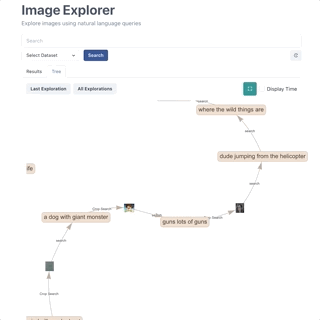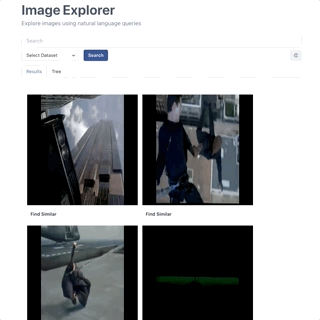
The tree in the video visualizes a few sampled trajectories generated using a language model. We use nucleus sampling to sample the model predictions and generate the sentence. The previous version of word tree used beam search. In general, nucleus sampling tends to generate diverse as well as better quality text. In my opinion, the idea is somewhat similar to the Adaptive noise scaling approach where we dynamically expand or contract the candidate pool or search radius.
By sampling text from the dynamic nucleus of the probability distribution, which allows for diversity while effectively truncating the less reliable tail of the distribution, the resulting text better demonstrates the quality of human text, yielding enhanced diversity without sacrificing fluency and coherence.
Source: The Curious Case of Neural Text Degeneration (i.e. The Nucleus Sampling Paper)
See Also
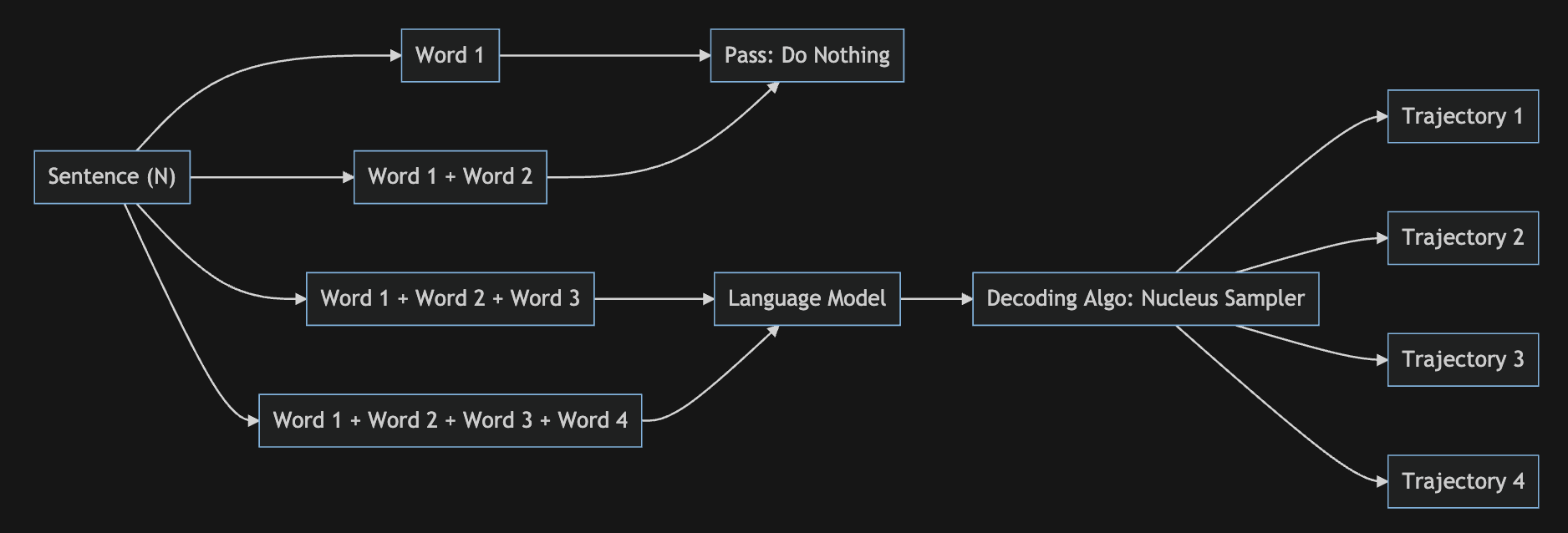
How does it work?
At the very high level, this is how it works:
- Split sentences into individual sentence
- Split each sentence into words
- For every word in a sentence, concatenate with previous words and pass through the language model
- Decode the model predictions to generate a complete sentence
Visually, the flow looks like this:
TODO: Add animated version with an example
A few points worth mentioning:
⇢ Why aren't we passing the first two words to the model? Well, technically, we could but having more context helps the model provide better predictions. For example, in the diagram above, we do not do anything for the first two words.
⇢ We can swap out the language model with any domain-centric or next state-of-the-art model
⇢ We can swap the decoding algorithm as well
⇢ What do you mean by trajectory? The trajectory here is the path taken by the sentence. Each trajectory is created by repeatedly sampling the next word until the stopping criteria is met. You can read about stopping criteria here
The rest of the post breaks down the demo in the video into individual plots.
Plots
Updated Video: Word Tree + Generative Image Model
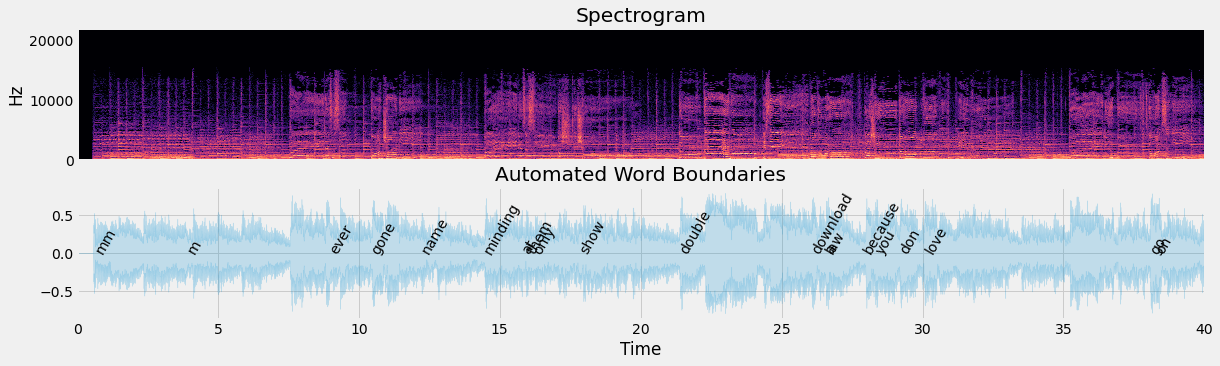
Both the the videos were created by manually aligning the song to the tree animation. You know what will be cool? Automatically aligning the audio and animation using word boundary detection.
The following example shows automated speech transcription using VOX along side the audio waveform plot using Librosa. The recognized text is not quite there but it is a start 😀.
Or do something even cooler ⬇

But I am going to stop here 😀. Hoping to see it in action some day.
Finally, I am going to leave you with the following thoughts. As I wrote them, I started looking for ways to visualize them. The animation and the post is my attempt to imagine these thoughts.
Trajectories are intriguing Of many choices available, only one that ever gets chosen. The rest become could've, should've, or would've. Every step, every moment, every decision presents many possible paths - infinitely branching. Some more likely than the others. But one must choose. Trajectories are fascinating
No language models were used to write this one
If you wish to explore more about sampling trajectories, you may find the following useful:
Up Next
Back to the demo app that has been in works for a few months now 😅
👨🏽💻....